
type
status
date
slug
summary
tags
category
icon
password
ESMM
1️⃣论文出处
2️⃣论文解读






3️⃣模型结构
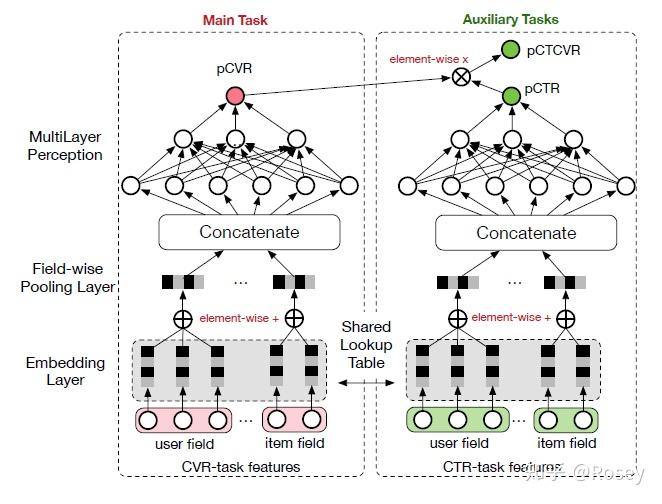
1)共享Embedding
CVR-task和CTR-task使用相同的特征和特征embedding,即两者从Concatenate之后才学习各自部分独享的参数;
2)隐式学习pCVR
啥意思呢?这里pCVR(粉色节点)仅是网络中的一个variable,没有显示的监督信号。

其中 z和y分别表示conversion和click。注意到,在全部样本空间中,CTR对应的label为click,而CTCVR对应的label为click & conversion,这两个任务是可以使用全部样本的。通过这学习两个任务,就能根据上式隐式地学习CVR任务。
4️⃣解决问题
1、样本选择偏差
转化是在点击之后发生,传统CVR预估模型在clicked数据上训练,但是在推理时使用了整个样本空间见图。训练样本和实际数据不服从同一分布,不符合机器学习中训练数据和测试数据独立同分布的假设。直观的说,会产生转化的用户不一定都是进行了点击操作的用户,如果只使用点击后的样本来训练,会导致CVR学习产生偏置。
2、训练数据稀疏
训练数据稀疏问题很明显,点击样本在整个样本空间中只占了很小一部分,而转化样本更少,高度稀疏的训练数据使得模型的学习变得相当困难。
5️⃣损失函数

ESMM的损失函数,其包含两个子任务CTR和CTCVR。并没有用CVR作为loss function。
6️⃣代码实现
工具:tensorflow


7️⃣论文细节
CVR&CTR任务的训练样本
CVR模型:点击label=1&转化label=0是负样本,点击label=1&转化label=1是正样本。
CTR模型:点击label=0是负样本,点击label=1是正样本。
CTCVR任务:点击label=0 和 点击label=1&转化label=0这两种情况都是负样本,点击label=1&转化label=1这种情况下才是正样本。
对于cvr任务
training space是: 点击且转化为正例,点击未转化为负例
Inference space是:对于所有曝光样本,计算该样本如果点击后,能成功转化的概率。
那么Inference space和training space在目标上本质上还是一致的,预估某条样本,在已点击的情况下,能成功转化的概率。
区别在于,training space中所有样本都已经点击了,所以是否成功转化已经有ground truth了。但Inference space中大量样本都没有点击,所以如果点击后否能成功转化,已经不得而知了。所以在单一的cvr训练过程中,这些样本只能被丢掉。
而在实际应用上,我们又经常需要对确定会曝光,但还未点击样本,预估其如果点击后的cvr,可我们的训练样本只在已点击数据上建模,会导致对未点击的这部分样本有偏,所以这就带来了SSB。
对于ctr预估的负样本,在计算loss更新参数时,cvr网络参数是否会更新
因为ctr网络的负样本也是cvr网络的负样本,cvr网络参数也会进行更新。
CTCVR的loss会影响CTR侧的非共享层吗?
CTCVR本来就该同时影响CVR & CTR, 它是这两个的乘。简单地说,CVR部分的梯度信息全部来自目的函数中CTCVR,而CTR部分来自CTCVR & CTR
- Author:liamtech
- URL:https://liamtech.top/article/10f9746b-4e13-8004-9405-d5d0ca8627d0
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!